Использование сценариев для DSO
В завершении лекции познакомимся с примером более сложного сценария, который использует DSO для работы с соответствующим набором записей XML-документа. В примере использованы методы и свойства объекта DSO recordset для поиска книг в документе Inventory Big.xml (см. Листинг 8.3). Приемы, используемые для поиска и отображения данных XML, подходят только для XML-документа, организованного как простой набор записей. (Что такое простой набор записей – см. в разделе "Использование одной HTML-таблицы для отображения простого набора записей" ранее в этой лекции.)
Подсказка. С более сложными примерами сценариев вы познакомитесь в лекции 9. Сценарии в этой лекции используют совершенно иной программный объект (объектную модель XML-документа – Document Object Model), который даст вам возможность работать с любыми типами XML-документов, а не только с документами, структурированными как набор записей.
В Листинге 8.15 представлена HTML-страница, содержащая пример сценария.
Листинг 8.15. Inventory Find.htm (html, txt)
HTML-страница отображает элемент INPUT типа TEXT, который разрешает пользователю ввести одну строку искомого текста:
<INPUT TYPE="TEXT" ID="SearchText">
Страница также отображает элемент BUTTON (кнопка) с надписью "Search":
<BUTTON ONCLICK='FindBooks()'>Search</BUTTON>
Когда пользователь щелкает мышью на кнопке, вызывается функция сценария FindBooks, которая извлекает искомый текст из элемента INPUT и просматривает названия из всех записей BOOK в XML-документе в поисках текста, после чего отображает найденные записи BOOK, содержащие этот текст, как показано на рисунке 8.9.
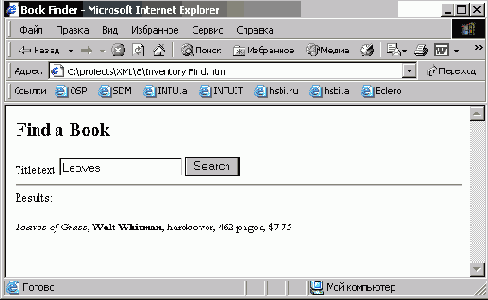
Рис. 8.9.
Функция FindBooks сценария содержится в элементе SCRIPT и написана на языке JSCRIPT:
<SCRIPT LANGUAGE="JavaScript"> function FindBooks () { SearchString = SearchText.value.toUpperCase(); if (SearchString == "") { ResultDiv.innerHTML = "<You must enter text into " + "'Title text' box.>"; return; } dsoInventory.recordset.moveFirst(); ResultHTML = ""; while (!dsoInventory.recordset.EOF) { TitleString = dsoInventory.recordset("TITLE").value; if (TitleString.toUpperCase().indexOf(SearchString) >=0) ResultHTML += "<I>" + dsoInventory.recordset("TITLE") + "</I>, " + "<B>" + dsoInventory.recordset("AUTHOR") + "</B>, + dsoInventory.recordset("BINDING") + ", " + dsoInventory.recordset("PAGES") + " pages, " + dsoInventory.recordset("PRICE") + "<P>"; dsoInventory.recordsetmoveNext(); } if (ResultHTML == "") ResultDiv.innerHTML = "<no books found>"; else ResultDiv.innerHTML = ResultHTML; } </SCRIPT>
Ссылка. Язык JScript является версией Microsoft языка написания сценариев JavaScript. (В нашем примере блока SCRIPT атрибут LANGUAGE задает родовое имя языка.) Полную информацию о JScript, включая учебник, вы можете найти на следующих Web-сайтах, предоставляемых MSDN: http://msdn.microsoft.com/workshop/c-frame.htm#/workshop/languages/jscript/handling.asp и http://msdn.microsoft.com/scripting/default.htm?/scripting/jscript/default.htm.
Сначала функция FindBooks получает текст, введенный через элемент INPUT (он имеет атрибут ID SearchText), а затем использует метод toUpperCase JScript для преобразования символов текста в прописные буквы. (Функция FindBooks преобразует текст в прописные, чтобы поиск осуществлялся без учета регистра.)
SearchString = SearchText.value.toUpperCase();
Если пользователь не ввел текст в поле INPUT, функция отображает сообщение и завершает свою работу:
if (SearchString == "") { ResultDiv.innerHTML = "<You must enter text into " + "'Title text' box.>"; return; }
ResultDiv есть идентификатор ID элемента DIV в нижней части страницы, который отображает результаты поиска. Присвоение текста (который может включать HTML-разметку) свойству innerHTML элемента DIV приводит к отображению этого текста (с учетом всей содержащейся в нем HTML-разметки).
Далее функция делает текущей первую запись XML, используя метод recordset.moveFirst, с которым вы познакомились ранее:
dsoInventory.recordset.moveFirst();
Затем она очищает строковую переменную, используемую для хранения HTML-разметки найденных результатов (ResultHTML):
ResultHTML = "";
После этого функция FindBooks выполняет цикл просмотра всех записей в XML-документе. Для анализа момента завершения цикла при достижении конца файла используется свойство recordset.EOF, а для перехода к новой записи используется метод recordset.moveNext:
while (!dsoInventory.recordset.EOF) { TitleString = dsoInventory.recordset("TITLE").value; if (TitleString.toUpperCase().indexOf(SearchString) >=0) ResultHTML += "<I>" + dsoInventory.recordset("TITLE") + "</I>, " + "<B>" + dsoInventory.recordset("AUTHOR") + "</B>, + dsoInventory.recordset("BINDING") + ", " + dsoInventory.recordset("PAGES") + " pages, " + dsoInventory.recordset("PRICE") + "<P>"; dsoInventory.recordset.moveNext(); }
В начале цикла функция получает значение поля TITLE для текущей записи:
TitleString = dsoInventory.recordset("TITLE").value;
Выражение справа от знака равенства представляет собой краткую нотацию вызова свойства fields объекта recordset. Полная нотация выглядит следующим образом:
TitleString = dsoInventory.recordset.fields("TITLE").value;
Свойство fields содержит множество всех полей, принадлежащих текущей записи. Чтобы получить доступ к определенному полю, следует поместить в скобках имя этого поля, и вы получите его содержимое как строку, через свойство value, добавленное в конце выражения.
Далее в цикле используется метод indexOf JScript для анализа, содержит ли название в текущей записи искомый текст. Если искомый текст обнаружен, код внутри оператора if добавляет к строке ResultHTML текст и HTML-разметку, требуемую для отображения текущей записи:
if (TitleString.toUpperCase().indexOf(SearchString) >=0) ResultHTML += "<I>" + dsoInventory.recordset("TITLE") + "</I>, " + "<B>" + dsoInventory.recordset("AUTHOR") + "</B>, + dsoInventory.recordset("BINDING") + ", " + dsoInventory.recordset("PAGES") + " pages, " + dsoInventory.recordset("PRICE") + "<P>";
По выходу из цикла функция назначает HTML-разметку, содержащую результаты, свойству innerHTML элемента DIV в разделе BODY документа, который используется для отображения этих результатов (данный элемент DIV имеет идентификатор ResultDiv):
if (ResultHTML == "") ResultDiv.innerHTML = "<no books found>"; else ResultDiv.innerHTML = ResultHTML;
Элемент DIV воспринимает HTML-разметку и сразу же отображает результаты.